

KDD (Knowledge
Discovery in Databases) é um processo de descoberta de conhecimento em bases de
dados que tem como objetivo principal extrair conhecimento a partir de grandes
bases de dados. Esse processo é utilizado na abordagem de Aprendizagem de Máquina,
ou seja, cria um modelo (sistema) que aprende com os dados históricos e assim
consegue identificar um registro novo como sendo de uma classe preditiva. Para isto ele envolve diversas áreas do conhecimento, tais
como: estatística, matemática, bancos de dados, inteligência artificial,
visualização de dados e reconhecimento de padrões. São utilizadas técnicas, em
seus diversos algoritmos, oriundas dessas áreas.
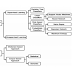
Esse processo envolve as etapas de coleta (seleção),
pré-processamento e/ou transformação, mineração e por último a interpretação/avaliação.

Coleta dos dados
A coleta de dados tem como função formar a base dados onde
será minerado o conhecimento valioso. A tarefa de coleta dos dados é crítica
porque os dados podem não estar disponíveis em formato apropriado para serem
utilizados no processo de KDD. Ou, mesmo se disponíveis, os dados podem
precisar ser rotulados com o auxílio de um especialista do domínio. Esse auxílio
é chamado de supervisionado (acesse o post, Aprendizado de Máquina para
entender sobre essa abordagem).
Pré-processamento
O Pré-processamento e/ou transformação são etapas que se
aglutinam e que o estado da arte denomina apenas de pré-processamento.
É realizado sobre os dados coletados com o intuito de
melhorar a qualidade dos mesmos, afim de prepará-los em uma forma estruturada
para serem submetidos à fase de mineração de dados. É a face mais complexa,
pois suas atividades são, por exemplo, a integração de dados heterogêneos,
eliminação de incompletude dos dados e aplicação de técnicas Processamento de
Linguagem Natural (NPL).
A limpeza dos dados envolve uma verificação da consistência das
informações, e o preenchimento ou eliminação de valores nulos e redundantes. Nessa
fase são identificados e removidos os dados duplicados e/ou corrompidos os
chamados “ruídos”.
Mineração
A mineração de dados é a etapa que é decidida quais os algoritmos
serão aplicados. Nessa etapa, pode-se utilizar diferentes áreas do
conhecimento, como Aprendizado de Máquina, Estatística, Rede Neurais e dentre
outros. Se o objetivo dessa fase é criar um modelo preditivo, então,
decidir qual algoritmo é ótimo para o problema que está sendo analisado não é uma
tarefa trivial. Esse fato ocorre pois a Aprendizagem de Máquina utiliza
diversos tipos de algoritmos que são, Associação, Clusterização, Árvore de
decisão, Regressão, Rede neural, Classificação e dentre outros.
Avaliação
Avaliação e interpretação de resultados são as últimas
etapas no processo de descoberta do conhecimento. É fase onde se avalia a performance
do modelo, onde se extrai o conhecimento.
Referências:



Gostou deste e de outros artigos, então Assine o [Descoberta de Conhecimento] por Email.



Nenhum comentário:
Postar um comentário